변화무쌍한 매핑맵 만들기
회사에서 일을 하면서 다음과 같은 과제가 생겼다.
특정 json 데이터가 외부로부터 전달된다. 이 데이터를 요구되는 Map구조에 맞추어 가공해야했다. 하나의 객체 안에 담겨야 할 내용이 여러 객체로 분산되어 전달되는 경우 이를 하나로 병합해야했다. 반대로 분리되어야할 정보는 각각 분할해야했다. 키를 변경하거나 값을 변경해야할 경우도 있었다.
문제는 전달되는 데이터의 구조가 프로젝트마다 변경될 수 있다는 것이다. 나는 처음에는 모든 경우의 수를 커버링 할 수 있는 만능 mapSchema 을 설계 했으나 좋은 방식이 아니었다. 인풋 데이터는 프로젝트에 따라 변하기 때문에 변환-가공로직도 유연하게 수정가능해야했다. 코드를 변경하지 않고 상황에 따라 데이터 변환 방식을 지정하고 수정할 수 있어야 했다.
나는 데이터처리 방식을 추상화하고 또한 원자화하여 데이터처리 파이프라인을 설계 했다. 우선 입력 인터페이스를 통일화 했다. 외부에서 전달되는 json 데이터를 깊이레벨과 관계 없이 일괄적으로 평면화 시켰다. 그것을 모아서 List<Map<String,String» 모아서 처리할 수 있게 단순화했다.
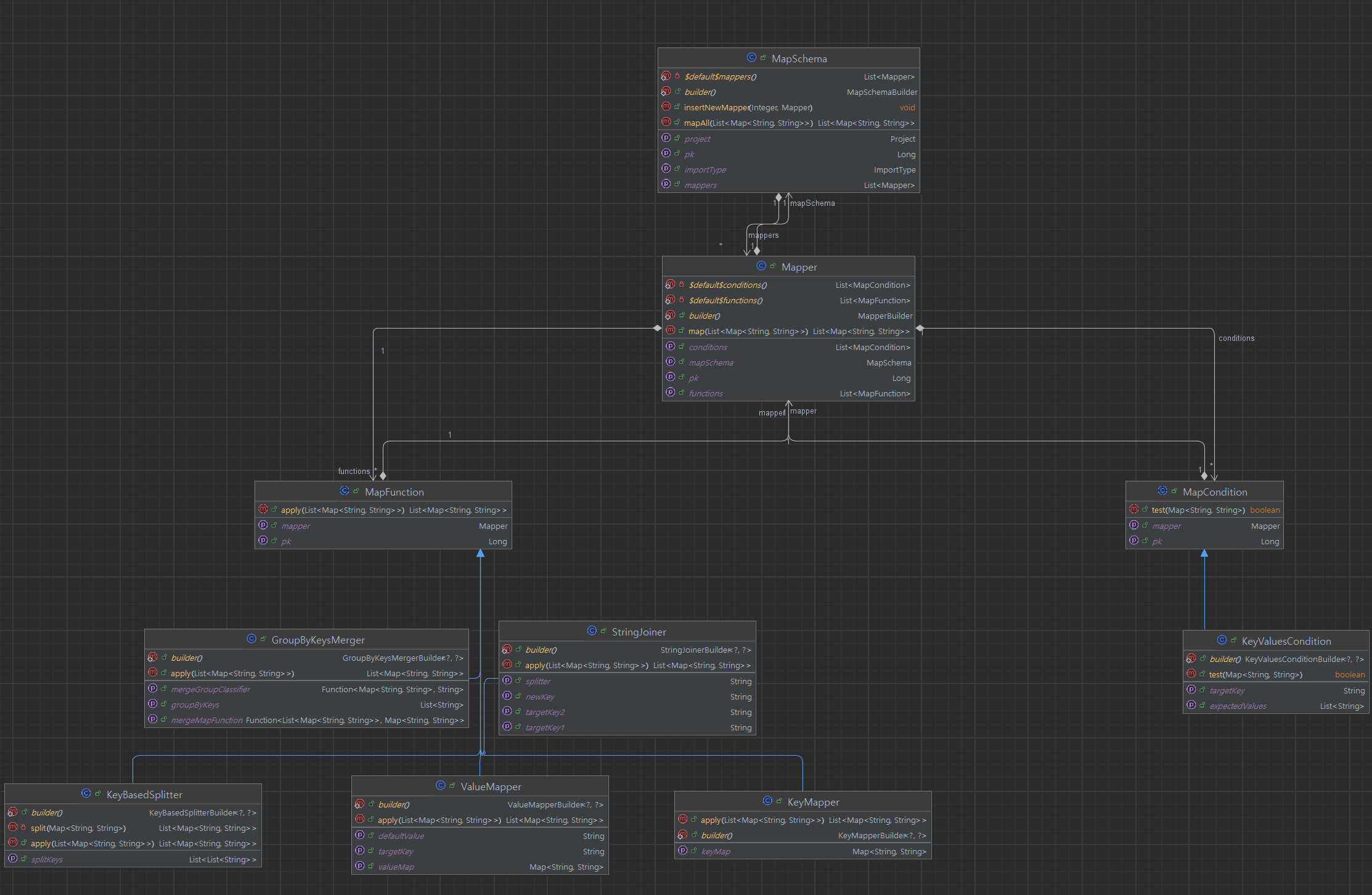
변경된 mapSchema 클래스는 커스텀 Mapper을 여러개 담을 수 있게 했다. 실제 데이터를 처리하는 것은 누적된 Mapper를 하나씩 경유하면서 작업된다. 따라서 메소드가 무척 단순해졌다. Mapper을 순서대로 실행하여 인풋데이터를 처리하면 되었다. Mapper를 담는 클래스는 예를 들어 다음과 같이 설계했다.
@Entity
public class MapSchema{
@OneToMany
private List<Mapper> mappers;
public List<Map<String,String>> doMap (List<Map<String,String>> maps){
mappers.foreach(Mapper::map);
return maps;
}
}
Mapper(매퍼)는 2가지 기능 사용하는 클래스다. 첫번째로 전달된 Map을 분석하여 Mapper가 해당 데이터를 처리할 것인지를 결정한다. 만약 처리할 데이터가 아니라면 그대로 흘려보내고 다음 데이터를 순서대로 분석한다. 이는 타겟체크 기능이다. 두번째 기능은 데이터를 조작하는 기능이다.
따라서 Mapper의 구조를 다음과 같이 설계했다.
@Entity
public class Mapper {
@ManyToOne
private MapSchema mapSchema;
@OneToMany(mappedBy = "mapper")
@OrderColumn
private List<MapCondition> conditions = new ArrayList<>();
@OneToMany(mappedBy = "mapper")
@OrderColumn
private List<MapFunction> functions = new ArrayList<>();
public List<Map<String,String>> map (List<Map<String,String>> maps){
List<Map<String,String>> targets = new ArrayList<>(maps);
for(MapCondition condition : conditions){
targets = targets.stream().filter(condition::test).toList();
}
maps.removeAll(targets);
for(MapFunction function : functions){
targets = function.apply(targets);
}
maps.addAll(targets);
return maps;
}
}
MapCondition 과 MapFunction는 추상클래스다.
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
@Entity
public abstract class MapCondition {
@ManyToOne
protected Mapper mapper;
public abstract boolean test(Map<String,String> map);
}
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
@Entity
public abstract class MapFunction {
@ManyToOne
protected Mapper mapper;
public abstract List<Map<String,String>> apply(List<Map<String,String>> maps);
}
각각의 추상클래스의 상속받은 클래스 예는 다음과 같다.
@DiscriminatorValue(value = "KEY_VALUES_CONDITION")
@Entity(name = "map_condition_key_values_condition")
public class KeyValuesCondition extends MapCondition {
private String targetKey;
@Convert(converter = ListToStringConverter.class)
private List<String> expectedValues;
@Override
public boolean test(Map<String, String> map) {
String actualValue = map.get(targetKey);
boolean isContained = expectedValues.contains(actualValue);
return isContained;
}
}
@DiscriminatorValue(value = "KEY_MAPPER")
@Entity(name = "map_function_key_mapper")
public class KeyMapper extends MapFunction {
@Convert(converter = MapToStringConverter.class)
private Map<String,String> keyMap = new HashMap<>();
@Override
public List<Map<String, String>> apply(List<Map<String, String>> maps) {
for(Map<String, String> map : maps){
keyMap.forEach((k, v) -> map.put(v, map.get(k)));
}
return maps;
}
}
id 필드 등을 제외한 예시이다.
이와 같은 설계로 여러가지 조건을 하나의 리스트에 담아서 다중 and 조건검사로 처리할 대상을 확인할 수 있다. 또한 여러가지 MapFunction을 리스트에 담아서 여러번에 걸쳐 원하는 조작을 수행 할 수 있다. 각각 추상클래스로 리스트로 담기기 때문에 필요한 만큼 조건검사 클래스, 조작 클래스를 만들어 다형성을 활용 가능하다.
중간에 이와 같은 설계를 하면서 한 고민들이 있다. 지나치게 @Entity를 많이 사용하고 있는 것이 염려되었다. 처음 계획했던 것은 @Embeddable 클래스를 특정 인터페이스에 피상속시켜 다형성을 구현하는 것이었는데 애플리케이션 레벨에서 DataAccess를 포함한 구현을 직접 해야해서 부담이 되었다.
그래서 생각한 것이 Serializable 를 상속시키고 매핑 객체를 db에 바이트코드로 저장하여 필요할 때마다 사용하는 것이었다. 그러나 이것은 별 효용이 없어 보였고 복잡도가 높아질 뿐 아니라 런타임시의 메소드가 어떻게 동작할지에 대한 예측과 유지보수가 어려울 것으로 보였다.
그래서 결국 최대한 데이터 조작을 가장 작고 변경이 필요 없는 수준까지 원자화하고 이를 각각 상속받는 엔티티로 설계하기로 했다. 그렇게 조건검사와 조작기능을 나누고 조작기능도 키를 바꾸는 것. 또는 밸류를 변경하는 것이나 합치거나 분할하는 등 각각이 서로 다른 기능을 의존하거나 포함하지 않도록, 또한 각각의 일렬의 실행만으로 복잡한 매핑도 가능할 수 있도록 설계 했다. 아래.
이제 외부에서 api로 각각의 conditions와 functions를 추가하거나 수정하는 것을 생각하게 되었다. @JsonTypeInfo 와 @JsonSubType으로 요청시 dto에 type 을 명시하고 이에 따라 다르게 객체를 가져올 수 있도록 변경했다.
//요청문
{
"type": "KEY_VALUES_CONDITION",
"targetKey": "이름",
"expectedValues": [
"김길동",
"김숙녀"
]
}
//dto
@JsonTypeInfo(use = JsonTypeInfo.Id.NAME, include = JsonTypeInfo.As.PROPERTY, property = "type")
@JsonSubTypes({
@JsonSubTypes.Type(name = "KEY_VALUES_CONDITION", value = KeyValuesConditionDto.class)
})
public interface MapConditionDto {
public MapCondition convertToNewOne(Mapper mapper);
}
public class KeyValuesConditionDto implements MapConditionDto {
private Long mapConditionPk;
private Long mapperPk;
private String targetKey;
private List<String> expectedValues = new ArrayList<>();
}
복잡도를 줄이기 위해서 Mapper와 그를 구성하는 conditions 와 functions는 리파지토리나 서비스를 따로 생성하지 않았다. 대신 그것을 실제로 구성해서 사용하는 MapSchema 클래스가 일종의 Aggregate로써 하위 엔티티를 관리할 수 있도록 책임을 부여했다. orphanRemoval로 리스트 참조가 끊겼을 때 자동으로 삭제될 수 있도록 구성했다.
public class MapSchema {
@Builder.Default
@OneToMany(mappedBy = "mapSchema", fetch = FetchType.LAZY, cascade = CascadeType.ALL, orphanRemoval = true)
@OrderColumn
private List<Mapper> mappers = new ArrayList<>();
public void insertNewMapper(int index, Mapper mapper) {
if(index < 0){
mappers.addFirst(mapper);
return;
}
if(index >= mappers.size()){
mappers.add(mapper);
return;
}
mappers.add(index, mapper);
}
}
이런 방식을 사용했을 때는 어쩔 수 없이 다형성을 상속을 위해 엔티티로 만든 Mapper와 그를 구성하는 conditions 와 functions를 마치 embeddable 클래스처럼 다룰 수 있다는 장점이 있다. 그러나 Entity가 아닌 것은 아니어서 여전히 식별자는 존재하고 기록된다. 그래서 해당 pk로 식별하고 엔티티를 다룰 여지도 생기는 것은 사실이다.
따라서 Mapper와 그 구성 클래스들을 MapSchema라는 상위 엔티티라는 단일한 경로로 다루도록 강제할 필요가 있다. MapSchema로 식별하고 Mapper 리스트의 인덱스 번호로 다룰 수 있도록 설계하는 것이다. API를 설계할 때 엔티티로 다루지 않을 객체들에 대해서의 식별자를 노출하지 않게 하거나 엔티티의 pk를 private, getter 메소드 제외로 설정할 수도 있다. 더불어 해당 객체들을 수정하는 작업을 기존 것을 삭제하고 새로운 것을 추가하는 방식으로하는 일종의 불변 객체를 다루듯 설계할 수 있다.