제대로 다루지 못한 예외를 핸들링하기
부족한 점 깨닫기
스프링부트는 웹의 기본설정으로 잡히지 못한 예외가 발생하면 요청 헤더에 따라 HTML 또는 JSON 형식으로 예외에 대한 내용을 응답한다. 아마 이런 기본 설정은 API를 디버깅 할때 쉽게 서버측에서 발생한 예외에 대한 내용을 파악할 수 있어서 기본 설정으로 둔 것 같다.
내가 담당하는 API 서버의 코드도 예외가 발생하면 지금까지 위와 같이 응답했다. Exception의 Stack Trace가 그대로 노출 되었는데 이는 물론 디버깅에 유리하지만 동시에 보안적으로 좋지 못했다. 애플리케이션의 구조가 선명히 드러나보이기 때문이다.
나는 개발을 하며 이런 방식으로 서버의 구조가 노출되는 것이 좋지 않다고 판단했고 이를 개선하기 위해 예외 발생시 노출되는 보안적인 정보는 최소화하고 또한 예외의 스택트레이스를 확인하기는 쉬운 방법을 탐구했다.
예외 응답시 응답에 포함되는 보안 정보를 최소화하기
일반적으로 제대로 잡히지 못한 예외는 스프링의 기본 예외응답로직을 거치기 때문에 @RestControllerAdvice 를 적용했다. 가장 단순한 예외 메세지만 전달하게 했다. 예로는 다음과 같다.
@RestControllerAdvice
public class GlobalExceptionHandler {
/** 핸들링 되지 못한 예상밖의 예외를 INTERNAL_SERVER_ERROR 에러로 파싱하여 클라이언트에게 응답합니다. 클라이언트에게 스택트레이스가 공개되지 않습니다.*/
@ExceptionHandler({Exception.class})
protected ResponseEntity<ErrorResponse> uncaughtException(Exception e) {
log.error("UncaughtException", e);
return ResponseEntity.internalServerError().body(e.getMessage());
}
}
예시는 가장 단순한 형태이지만 많은 API서버에서 예외나 에러에 대한 응답으로 정형화된 Class를 사용한다. ErrorResponse.toResponseEntity(…) 등의 방식으로도 팩토리 메서드로 ResponseEntity를 만들어 응답에 사용하기도 한다.
예외의 스택 트레이스를 확인하기 : Slack
앞서 설정한 어드바이스로 예외에 대한 로그는 애플리케이션에만 남게 된다. 일반적으로 서버 리소스로 EC2를 많이 사용하는데 예외 로그를 보기 위해서 EC2로 매번 접속하는 것은 무척 성가신 일이다. 또한 담당하는 스테이지가 개발과 운영으로 나뉠텐데 각 스테이지 별로 로그를 집계하는 것도 무척 어렵다.
그래서 생각한 가장 간단하면서 쉬운 방식은 Logback 설정과 Slack을 사용하는 것이었다. 여기서 따로 그 설정방법을 다루지는 않겠다. 나는 각 스테이지 별로 로그 설정 파일을 분리하고 각각 원하는 채널에 예외로그를 수신 받도록 설정했다.
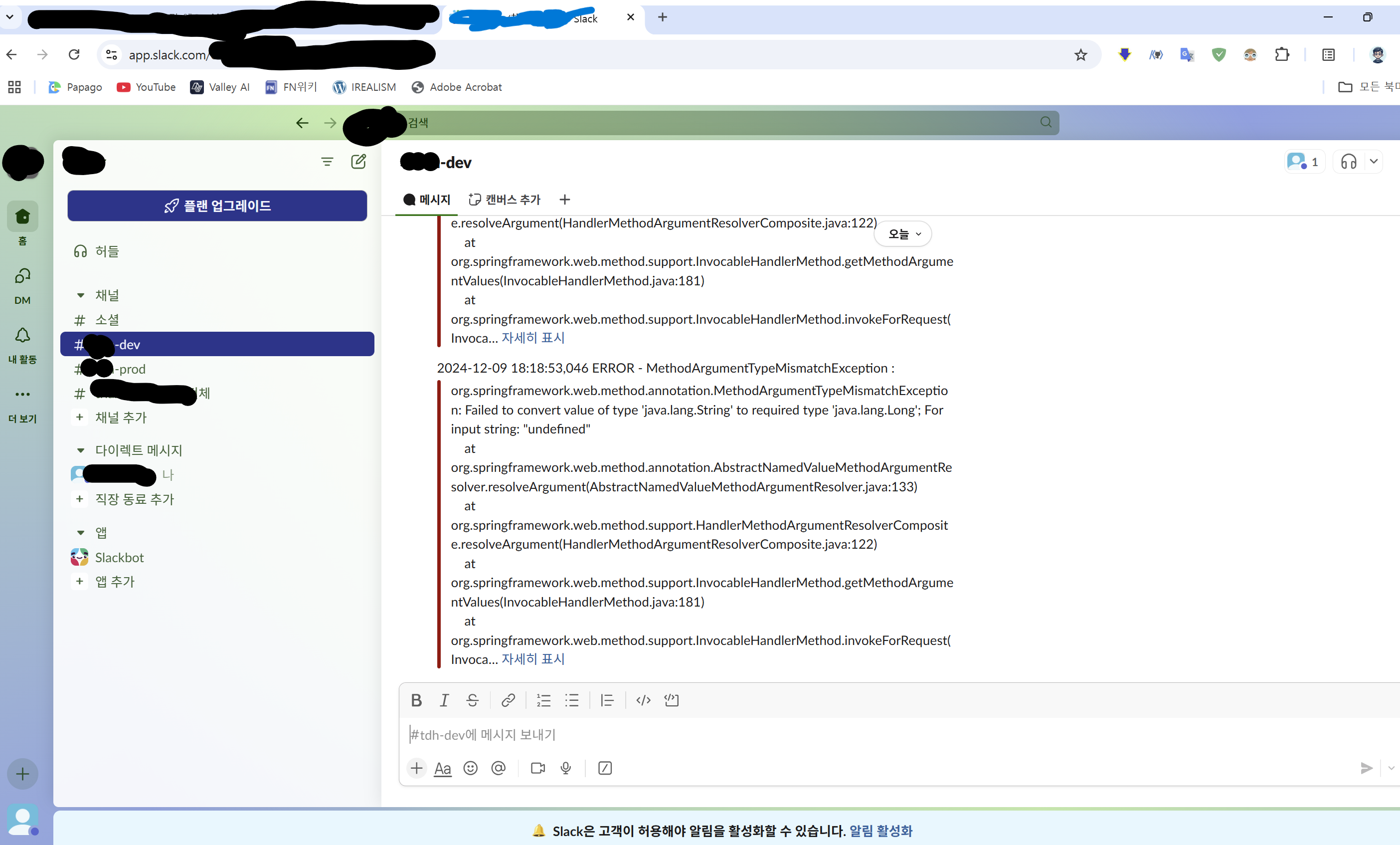
일반적으로 핸들링 되지 않은 예외를 우선적으로 모니터링할 수 있도록 설정했다. 또한 추가적으로 앞서 예시로 든 것 외로 MethodArgumentNotValidException 와 MethodArgumentTypeMismatchException 에 대해서도 예외 어드바이스를 설정하고 모니터링 했다. MethodArgumentNotValidException 는 자바 표준 자카르타 밸리데이션 애노테이션으로 설정된 요청 DTO의 밸리데이션에 실패했을 때에 발생되게 되는데, 주로 클라이언트에서 밸리데이션을 함에도 클라이언트 사이드의 코드가 커버하지 못하는 부분을 모니터링하기 위함이다. MethodArgumentTypeMismatchException 도 마찬가지로 클라이언트 사이드에서 가끔 잘못된 타입으로 파라미터를 매핑한 경우가 있기도 하기 때문에 이를 핸들링하기 위한 어드바이스로 설정했다. 이 두 예외는 MethodArgumentNotValidException.getBindingResult().getAllErrors() 와 같은 메소드나 MethodArgumentTypeMismatchException.getName(), .getValue() 와 같은 메소드를 가지고 있는데 이 정보를 잘 활용하면 적절한 예외 메시지를 자동화하여 응답할 수 도 있다.
또한 이러한 로그 모니터링은 비동기 이벤트로 로직을 구현할 때 많은 도움이 된다. 이벤트로 구현한 비동기작업은 실행 중에 발생한 예외가 이벤트를 발생시킨 클라이언트에게 전달되지 않고 애플리케이션 내부에서 예외발생 로그가 숨겨진다. 개발자는 이러한 모니터링을 통해서 예외 발생을 즉시 알 수 있다.
API 서버의 예외처리
최근 API서버에서 예외가 발생할 때 클라이언트로 보내는 에러 메세지를 가공없이 그대로 사용자에게 보여주는 프론트엔드 로직을 보았다. 이것은 테스트 용으로는 유용하겠지만 실제 서비스에서는 좋지 못한 방법이라고 생각했다. 우선 API서버의 예외 메세지는 매우 개발자에게 이해하기 쉬운 형식이고 일반 사용자는 이해하기 힘들다. 또한 같은 API를 여러 다른 stateful 한 유즈케이스에서 사용하는 구성을 할 경우 에러 메세지가 그 환경에 따라 변화하지 않으므로 사용자 접근성도 떨어진다. 내가 담당하는 솔루션의 몇몇 로직이 그런 상황이었으며 이런 구조는 개선해야한다고 생각했다.
찾아본 여러 사례들이 API에서 예외가 발생할시 자체적인 에러코드도 함께 응답하는 것을 알게되었다. 이러한 에러코드는 사전에 정책으로 명시된 기준에 따라 API SPEC에 포함되어야하며 클라이언트 사이드에서는 이러한 에러코드를 수신하고 사용자에게 현재 유즈케이스 환경에 따른 적절한 에러 메세지를 출력해줘야 한다.
예외 계층화
우리가 레이어드 아키텍쳐로 서버를 설계한다면 예외도 계층화되어야 한다. 웹 요청에 대한 예외는 컨트롤러나 서비스 영역에서 존재해야한다. 그 밖에 도메인 로직에 대한 예외는 서비스와 구현레이어 안에서 존재해야 한다. 리파지토리 레이어나 유틸리티에서 발생하는 예외 또한 그 영역에서만 던져져야 한다. 만약 Controller Advice가 잡아서 웹 요청에 대한 자동 응답을 하게되는 클라이언트 향 예외가 도메인 로직, 유틸이나 리파지토리 레이어에서 던져지게 된다면 그 계층의 결합도가 증가하게 되고 나중에 유지보수하기가 어려워진다.