데이터중심 애플리케이션 설계 요약
데이터중심 애플리케이션 설계 요약
데이터 중심 애플리케이션 설계

읽고 요약한다.
서문
Q. 왜 데이터 중심인가? A. 모던 애플리케이션은 일반적으로 다양하고 많은 데이터를 일관성 있게 느리지 않게 처리하는 것이 병목으로 지적되기 때문임. 이런 부분을 생각하며 애플리케이션을 설계해야함.
1장. 신뢰할 수 있고 확장 가능하며 유지보수하기 쉬운 애플리케이션
- 신뢰성: 각종 서비스 장애 사례를 통해 강조
- 확장성: 부하를 함수로 표현가능함. 시스템이 요구받는 부하를 계산할 필요 ex) 초당 트윗작성과 n개 트윗노출 m개. 응답시간을 성능지표로 삼으면 중앙값 분위를 p50 특이값은 p95~99로 확인할 수 있다. 이런 백분위 값은 SLO, SLA 계약서에 자주 나타난다. 부하 대응에 대해 비상태성 서비스는 스케일 아웃에 유리하지만 전통적인 상태성 서비스(데이터베이스)는 까다롭다.
- 유지보수성: 레거시 시스템의 고통을 최소화하기 위해서는 운영이 쉽고 쉽게 변경할 수 있는 단순한 시스템(코드)을 만들어야한다. 핵심은 추상화.
2장. 데이터모델과 질의언어
이 장에서는 관계형, 문서형, 그래프형 데이터 모델에 대해 다음을 설명한다.
- 역사적 배경
- 지역성과 관계의 복잡성에 따른 데이터 모델의 적합도
- 명령형과 선언형 질의
- 데이터 베이스와 사용하는 질의언어 예제
중요한것은 각 데이터모델이 유능함이 어느 한쪽을 완전히 대체하지 못한다는 점이다. 그래서 필요에 따라 함께 사용해야한다. 내 생각에 서비스의 도메인 모델에 따른 데이터 모델 선택이 1순위겠지만 시스템 전체의 복잡도를 고려하여 사용하는 데이터 모델의 수를 늘리지 않는 판단은 합리적일 수 있다. 예를 들어 어느정도 성능이 보장된다면 관계형 포스트그리큐엘과 같은 관계형 데이터베이스에서 JSONB 컬럼을 저장하여 조회시 복잡한 조인을 줄일 수도 있다. 상황에 따른 트레이드 오프가 필요하다.
3장. 저장소와 검색
먼저 로그구조 계열 저장소 엔진에 대해 설명을 한다.
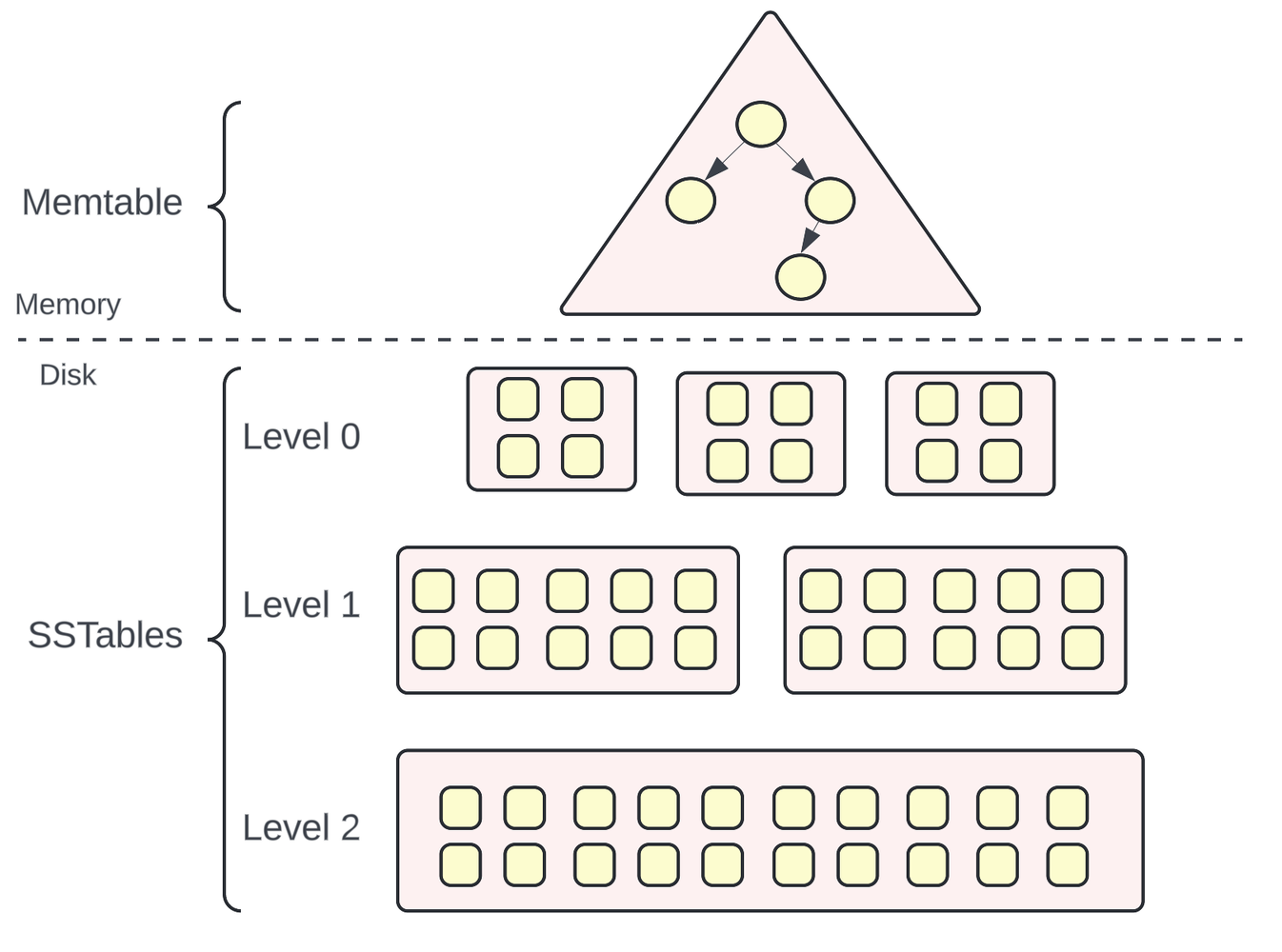
- 로그 계열은 어느 파일의 끝에 로그를 새줄로 추가하는 것과 같다. 간단하고 쓰기 성능이 좋고 읽기 성능이 아쉬운 편이다.
- 하나의 파일만 수정하면 크기가 너무 커지기 때문에 메모리 테이블 -> 디스크의 1레벨 부터 최종 6레벨까지 세그먼트를 나눈다. 각 단계에서 컴팩션을 통해 정렬하고 아래 단계 세그먼트로 저장하게 된다. 최신 정보가 나중에 저장되기 때문에 위에서 부터 조회하면된다.
- 단순하게 읽기 속도를 위해서 비트캐스크 같은 방식으로 인메모리 해시맵으로 키를 색인할 수 있다. 또는 세그먼트별 저장된 키를 해시함수에 통과시켜 나온 값을 바탕으로 존재 확률을 평가할 수 있는데 이를 통해 조회속도를 높일 수 있다.
- 레벨이 낮은 쪽은 작은 버퍼를 가지고 버퍼가 찰때 쯤 다음 레벨의 데이터를 가져와서 최신화하고 그 레밸에 세그먼트를 저장한다. 다음레밸로 갈수록 다루는 키의 범위와 세그먼트 수가 커지고 정리가 된다고 보면된다.
This post is licensed under CC BY 4.0 by the author.